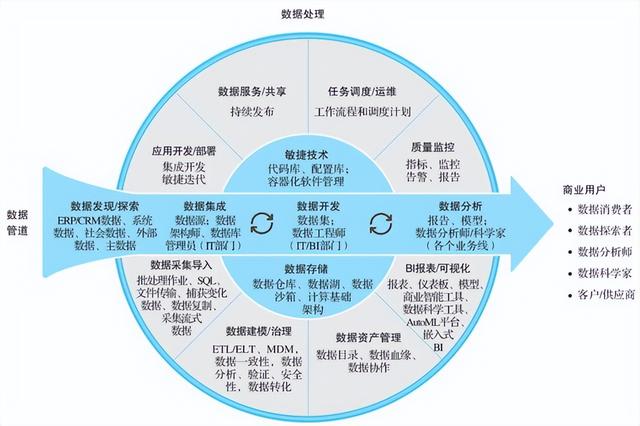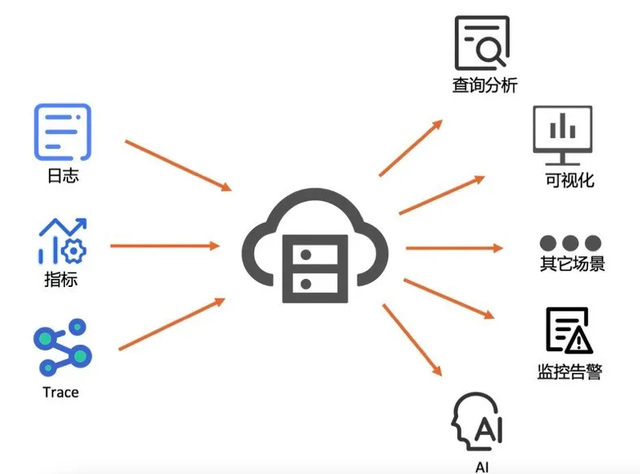
在数据产品的构建过程中,数据处理服务作为连接原始数据与最终业务价值的关键枢纽,其设计原则与架构实现直接决定了产品的性能、可靠性与扩展性。本文将深入探讨数据处理服务的设计原则,并解析其核心架构的实现路径。
一、数据处理服务的设计原则
1. 可扩展性原则
数据处理服务需具备水平扩展能力,以应对数据量激增或计算复杂度提升的场景。设计时应采用微服务架构,将数据处理任务拆分为独立的、可复用的服务单元,通过容器化技术实现资源的弹性伸缩。
2. 可靠性原则
数据处理的准确性至关重要。服务需内置容错机制,如数据校验、异常重试与事务回滚,确保数据处理流程的最终一致性。通过多副本存储与故障自动转移,保障服务的高可用性。
3. 实时性与批处理平衡原则
根据业务需求,灵活支持实时流处理与离线批处理。实时处理适用于对时效性要求高的场景(如监控告警),而批处理则适合大规模历史数据分析。架构上可通过Lambda或Kappa架构实现两者的协同。
4. 数据血缘与可追溯性原则
数据处理服务应记录完整的数据血缘信息,包括数据来源、转换过程与输出流向。这有助于问题排查、影响分析及合规审计,提升数据治理的透明度。
5. 安全性原则
在数据处理各环节实施加密、脱敏与访问控制,防止数据泄露与篡改。尤其对于敏感数据,需遵循最小权限原则,并定期进行安全审计。
二、数据处理服务的架构实现
- 分层架构设计
- 接入层:负责数据采集与接入,支持多源异构数据(如数据库日志、API接口、文件上传)的实时同步。常用工具包括Apache Kafka、Flume等。
- 处理层:为核心计算层,根据业务逻辑进行数据清洗、转换、聚合与建模。可选用Spark、Flink进行分布式计算,或使用Airflow、DolphinScheduler编排批处理任务。
- 存储层:提供分层存储方案,如将热数据存入HBase、Cassandra以供实时查询,冷数据归档至HDFS或云存储。利用数据湖技术实现原始数据与加工数据的统一管理。
- 服务层:通过API网关暴露数据处理能力,支持RESTful或gRPC接口,供下游应用调用。结合缓存机制(如Redis)提升高频查询性能。
- 关键组件与工具链
- 流处理引擎:Apache Flink凭借其低延迟、高吞吐的特性,成为实时处理的优选;对于复杂事件处理,可结合Esper或Spark Streaming。
- 批处理框架:Apache Spark的弹性分布式数据集(RDD)与结构化API,适用于大规模数据的迭代计算与机器学习任务。
- 任务调度器:Apache Airflow通过DAG(有向无环图)定义任务依赖关系,实现可视化监控与自动化重试。
- 数据质量监控:集成Great Expectations或Deequ等工具,定义数据质量规则,实时检测异常并告警。
3. 实践案例:实时用户行为分析管道
以电商场景为例,数据处理服务可构建如下管道:用户点击流数据经Kafka接入,由Flink实时过滤无效记录、解析行为事件,并聚合为会话级指标;结果实时写入ClickHouse供仪表盘展示,同时同步至HDFS留存原始日志。批处理任务每日凌晨启动,通过Spark计算深度指标(如用户留存率),并更新数据仓库。整个流程通过数据血缘工具追踪,确保端到端的可观测性。
三、挑战与演进方向
当前数据处理服务仍面临挑战:一是复杂业务逻辑下,流批一体架构的运维成本较高;二是数据隐私法规(如GDPR)对跨境数据处理提出更严要求。未来演进将聚焦于:
- 云原生与Serverless化:利用Kubernetes与函数计算(如AWS Lambda),进一步降低资源管理负担。
- AI增强的数据治理:引入机器学习自动识别数据模式、优化处理链路,并智能预警潜在风险。
- 边缘计算集成:在物联网等场景中,将部分处理任务下沉至边缘节点,减少中心集群压力并提升实时响应能力。
优秀的数据处理服务需以原则为纲,以架构为基,在动态平衡性能、成本与安全的过程中持续迭代。唯有如此,数据产品方能真正赋能业务,驱动智能决策。